


Depuis la sortie en 2024 du nœud AI Agent, n8n a basculé vers une logique d'orchestration : un workflow ne suit plus un chemin fixe, il reçoit une mission et choisit lui-même les outils à actionner. La raison est simple : les workflows déterministes s'effondrent dès que le monde réel s'en mêle.
Un workflow traditionnel, c'est un script déguisé. Si email contient "urgent", alors envoyer alerte Slack. Ça marche parfaitement... jusqu'au premier cas imprévu. L'agent IA, lui, reçoit une mission et décide lui-même comment l'accomplir. C'est la différence entre un formulaire et un collaborateur.
Voici pourquoi les agents n8n ont pris l'avantage, et comment construire le vôtre dès aujourd'hui.
Vous préférez confier ce chantier à une équipe qui le fait au quotidien ? Notre agence n8n conçoit, intègre et met en production vos agents et vos automatisations sur mesure.
Ce qu'un agent n8n peut faire que les workflows classiques ne peuvent pas
Un workflow classique est déterministe par nature. Vous définissez chaque branche, chaque condition, chaque sortie possible. C'est sa force pour des tâches répétitives prévisibles. C'est aussi son plafond.
L'agent n8n fonctionne différemment. Il reçoit un objectif en langage naturel, choisit les outils disponibles dans l'ordre qui lui semble pertinent, s'autocorrige si un outil échoue, et produit un résultat. Trois capacités que le workflow classique n'a tout simplement pas :
- Raisonnement contextuel : l'agent lit le contenu d'un email, d'un ticket ou d'un document et adapte son comportement au sens, pas au format.
- Gestion de l'ambiguité : si la demande est floue, il peut demander des précisions ou choisir l'interprétation la plus probable.
- Boucles d'auto-correction : si l'appel API échoue ou que le résultat est incohérent, il réessaie avec une stratégie différente.
- Mémoire conversationnelle : il garde le contexte des échanges précédents dans une même session.
Conséquence pratique : un workflow de qualification de leads nécessite 40 branches pour couvrir les cas courants. Un agent en gère 10 fois plus avec un seul noeud LLM et 3 outils connectés.
Architecture d'un agent n8n : mémoire, outils, LLM
n8n implémente les agents via LangChain.js. L'architecture suit un modèle en couches que vous assemblez visuellement.
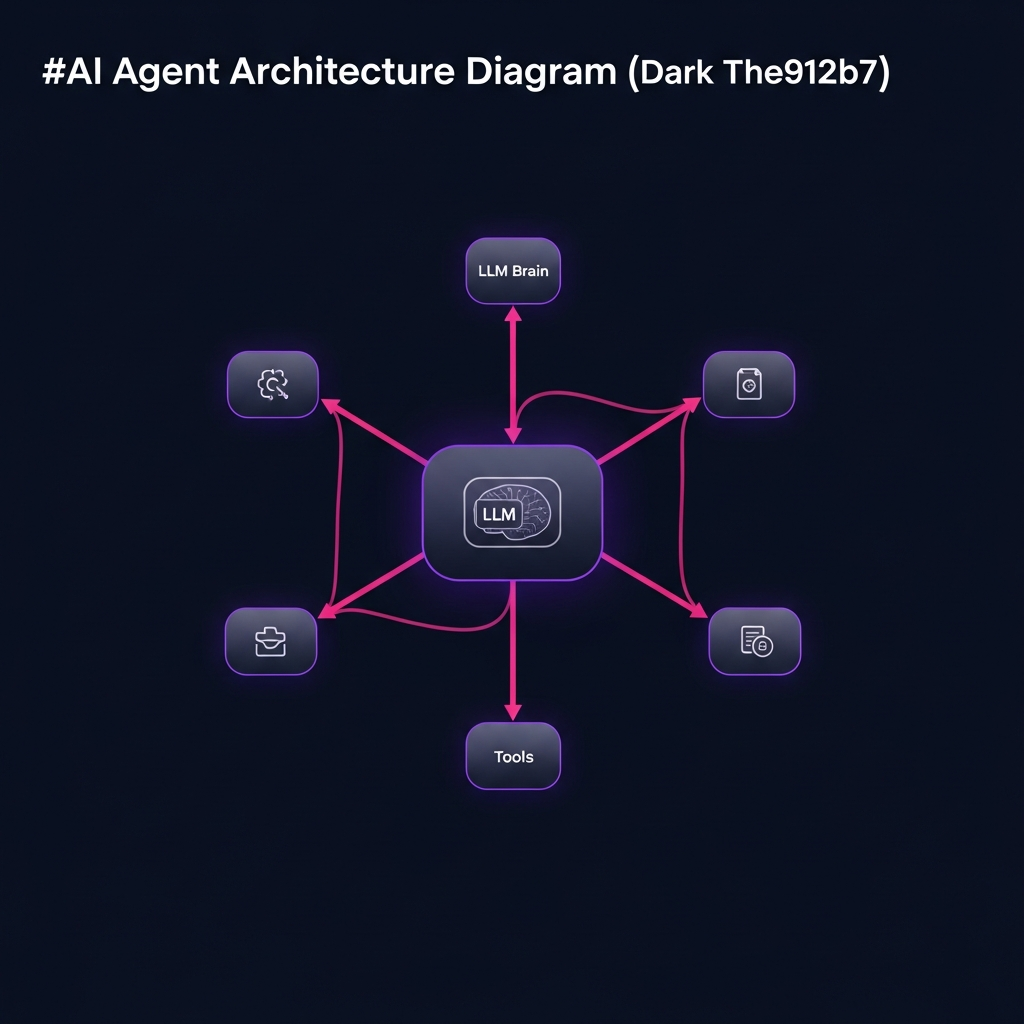
Le noeud central est l'AI Agent node. Il joue le rôle d'orchestrateur : il reçoit l'instruction, interroge le LLM, choisit les outils à appeler et synthétise la réponse finale.
Trois sous-noeuds s'y connectent :
- Le LLM (OpenAI GPT-4o, Claude 3.5, Mistral, Gemini, Ollama...) fournit le raisonnement. C'est le cerveau.
- La mémoire (Window Buffer Memory, Redis Memory) conserve le fil de la conversation. Sans mémoire, chaque message repart de zéro.
- Les outils (Tool nodes) : n'importe quel workflow n8n peut être exposé comme outil. L'agent accède ainsi aux 400+ intégrations de la plateforme sans code supplémentaire.
Le flux d'exécution suit un cycle ReAct (Reason + Act) : le LLM raisonne sur l'état courant, décide d'une action, l'exécute via un outil, observe le résultat, raisonne à nouveau. Ce cycle se répète jusqu'à ce que l'objectif soit atteint ou qu'un maximum d'itérations soit atteint.
Point important : la mémoire ne persiste pas entre sessions distinctes par défaut. Pour une mémoire longue durée, il faut connecter une base vectorielle (Qdrant, Pinecone) ou utiliser Redis avec persistance.
Construire votre premier agent n8n : étapes pratiques
Voici la structure minimale fonctionnelle. Sur votre canvas n8n :
- Ajoutez un Chat Trigger (ou Webhook si vous voulez l'appeler depuis une autre app).
- Connectez un noeud AI Agent. Dans les paramètres, définissez le prompt système : le rôle de l'agent, ses contraintes, ce qu'il doit ou ne doit pas faire.
- Reliez un noeud OpenAI Chat Model (ou autre LLM) à l'entrée "AI Language Model" de l'agent.
- Ajoutez un Window Buffer Memory à l'entrée "AI Memory". Réglez la fenêtre sur 10-20 messages.
À ce stade, vous avez un chatbot avec mémoire. Pour en faire un vrai agent, ajoutez des outils.
Créez un workflow séparé qui fait une action précise (chercher dans votre CRM, envoyer un email, créer un ticket). Puis ajoutez un noeud Call n8n Workflow Tool lié à votre agent. Décrivez l'outil en langage naturel : "Recherche un contact dans HubSpot par email et retourne son statut." L'agent appellera cet outil quand il jugera la situation pertinente.
Deux erreurs fréquentes à éviter. Un prompt système trop vague ("tu es un assistant utile") produit des agents imprévisibles. Soyez précis sur le périmètre. Et ne connectez pas plus de 5-6 outils sur un premier agent : le LLM se perd dans le choix.
Workflow classique vs agent IA : quand choisir quoi
| Critère | Workflow classique | Agent IA n8n |
|---|---|---|
| Tâches répétitives prévisibles | Parfait | Surdimensionné |
| Traitement de contenu non structuré | Limité | Natif |
| Gestion de cas imprévus | Requiert des branches manuelles | Autonome |
| Coût d'exécution | Faible (pas d'appel LLM) | Plus élevé (tokens LLM) |
| Débugage | Simple, traçable | Moins prévisible |
| Temps de mise en place | Rapide | Quelques heures |
La règle de base : si vous pouvez écrire l'algorithme sur un post-it, faites un workflow. Si le problème nécessite de lire, comprendre et décider, faites un agent. Ne remplacez pas vos workflows existants pour le principe. Combinez les deux.
Cas d'usage concrets
Triage et réponse aux emails support. L'agent reçoit chaque email, analyse la nature de la demande (bug, question facturation, demande de fonctionnalité), consulte la base de connaissances via un outil RAG, rédige une réponse adaptée et l'envoie si sa confiance dépasse un seuil. Il escalade aux humains si la demande est ambiguë. Un workflow classique aurait besoin de mots-clés et de branches pour chaque cas. L'agent gère les formulations imprévues naturellement.
Qualification de leads entrants. Dès qu'un prospect remplit un formulaire, l'agent enrichit son profil (LinkedIn, Clearbit), évalue son adéquation avec l'ICP, rédige un email de réponse personnalisé et crée l'opportunité dans le CRM avec le bon stade et la bonne priorité. Le tout en 30 secondes sans intervention humaine.
Veille concurrentielle automatisée. Chaque matin, l'agent scrape les pages de tarification des concurrents désignés, compare avec les données de la semaine précédente, identifie les changements significatifs et envoie un résumé Slack uniquement si quelque chose a changé. Pas de bruit, uniquement les signaux pertinents.
Ces scénarios ne sont pas des témoignages clients. Ce sont des patterns documentés dans les exemples officiels n8n et reproductibles avec les noeuds natifs de la plateforme.
FAQ
Un agent n8n peut-il remplacer un développeur Python pour des automatisations complexes ?
Pour 80 % des cas d'usage métier, oui. n8n donne accès à 400+ intégrations et au raisonnement LLM sans code. Pour des logiques très spécifiques (traitement de données binaires, algorithmes propriétaires), le noeud Code permet d'injecter du JavaScript directement dans le flux.
Combien coûte un agent n8n en production ?
Le coût principal est celui des tokens LLM. Avec GPT-4o mini à 0,15 USD / million de tokens en entrée et 0,60 USD / million en sortie (OpenAI API pricing), un agent qui traite 1 000 emails par mois consomme typiquement 2 à 5 USD de tokens selon la complexité. Ajoutez le plan n8n Cloud Starter à 20 €/mois (annuel) pour 2 500 exécutions (n8n.io/pricing), ou un hébergement auto via Docker. Voir notre guide installer n8n avec Docker.
Peut-on connecter plusieurs agents entre eux ?
Oui. n8n supporte les architectures multi-agents : un agent orchestrateur délègue à des agents spécialisés via des outils de type "Call n8n Workflow". C'est la base des systèmes agentiques avancés. La doc officielle n8n appelle ça les cluster nodes.
Mon agent peut-il apprendre de ses erreurs ?
Dans une même session, oui : la mémoire conversationnelle lui permet de corriger son approche. Entre sessions, non, à moins de mettre en place une boucle de feedback qui stocke les corrections dans une base de connaissances que l'agent consulte comme outil.
Vous voulez déployer un agent n8n adapté à vos processus métier, sans passer des semaines sur la configuration ? Notre équipe conçoit et met en production des agents IA opérationnels. Discutez de votre projet avec nous.


