Infrastructure IA en entreprise : poser les bonnes bases avant d'investir

La plupart des entreprises découvrent leurs besoins en infrastructure IA au mauvais moment : après avoir signé avec un fournisseur, après avoir lancé un POC, ou après avoir réalisé que leurs données ne peuvent pas quitter la France. Ce guide part de l'autre bout : d'abord comprendre l'architecture, ensuite choisir les outils.
En 2026, selon Gartner, les dépenses mondiales liées à l'IA atteignent 2 590 milliards de dollars, en hausse de 47 % sur un an. Plus de 45 % de cette somme - soit plus de 1 165 milliards de dollars - concernent directement l'infrastructure IA. Les grandes entreprises ne dépensent pas autant par effet de mode.
Les 4 couches que personne ne vous explique
Une infrastructure IA n'est pas un serveur puissant avec ChatGPT dessus. Elle comporte quatre couches distinctes, chacune avec ses propres contraintes de coût, de sécurité et de maintenance.
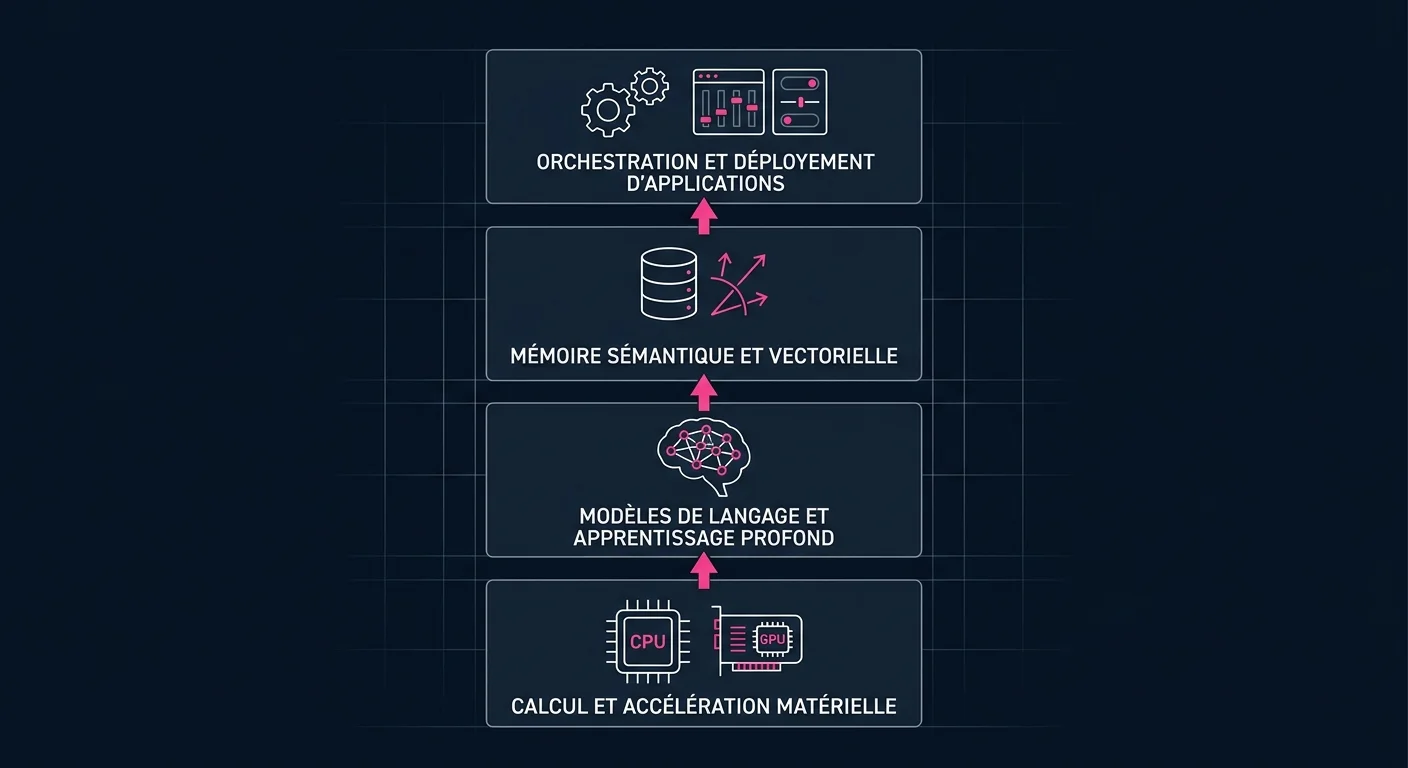
1. Le compute : GPU, CPU, et les compromis
Le compute désigne la puissance de calcul brute. Pour entraîner ou affiner des modèles, les GPU sont indispensables. Pour de l'inférence légère - faire tourner un modèle déjà entraîné sur un volume modéré de requêtes - des CPU bien dimensionnés suffisent souvent.
Les cartes H100 d'Nvidia dominent le marché professionnel. En on-premise, elles coûtent entre 25 000 et 40 000 euros par unité. Un serveur de 8 GPU représente entre 350 000 et 400 000 euros de matériel seul, sans compter l'électricité, le refroidissement, le réseau et les équipes pour le maintenir. Sur 5 ans, le matériel ne représente que 35 % du coût total de possession : le reste, ce sont les opérations.
En cloud, chez OVHcloud, une instance L4 (24 Go GDDR6) commence à 0,75 € HT/heure. Une H100 (80 Go HBM2e) coûte 2,80 € HT/heure. Ces prix rendent le cloud très compétitif pour des charges inférieures à 12 heures par jour d'utilisation continue.
2. Les modèles : API vs hébergement propre
Utiliser GPT-4o via l'API OpenAI ou Claude via l'API Anthropic, c'est ne pas avoir d'infrastructure modèle à gérer. Pratique pour démarrer, mais les données partent aux États-Unis, et les coûts d'API deviennent significatifs à volume.
Héberger un modèle en propre (Mistral, LLaMA, Gemma) demande au minimum une instance GPU et un outil de serving comme vLLM ou Ollama. En contrepartie, les données ne quittent pas votre infrastructure, et le coût marginal devient quasi nul passé l'amortissement du compute. Pour les entreprises soumises au RGPD sur des données sensibles, ce n'est pas un choix technique - c'est une obligation.
3. Les données et la couche RAG
La plupart des projets IA en entreprise ne consistent pas à entraîner un nouveau modèle, mais à faire répondre un modèle existant sur la base de vos données internes : contrats, manuels, tickets support, CRM. C'est l'architecture RAG (Retrieval-Augmented Generation).
Elle nécessite une base de données vectorielle (Qdrant, pgvector, Weaviate) pour stocker les représentations sémantiques de vos documents, et un pipeline d'ingestion pour convertir vos fichiers en vecteurs via un modèle d'embedding. Pour un projet de taille intermédiaire - 10 millions de documents et 100 000 requêtes par jour - le coût d'embedding seul atteint 50 à 100 dollars par jour. Ramené sur un mois, l'infrastructure RAG complète dépasse souvent plusieurs milliers d'euros.
Si vous cherchez un point de départ concret sur la mise en place d'agents IA sur mesure pour votre entreprise, la couche RAG est presque toujours le premier chantier à adresser.
4. L'orchestration et la supervision
Sans couche d'orchestration, votre infrastructure IA est une boîte noire. MLflow est l'outil open source le plus adopté pour le suivi des expériences et la gestion du cycle de vie des modèles. À côté, il faut un système de monitoring des latences (TTFT - temps avant le premier token - cible : sous 2 secondes), un registre de modèles, et des alertes en production.
C'est la couche la plus souvent sous-estimée dans les budgets initiaux. Et celle qui fait la différence entre un POC qui fonctionne une fois et une solution qui tourne fiablement à l'échelle.
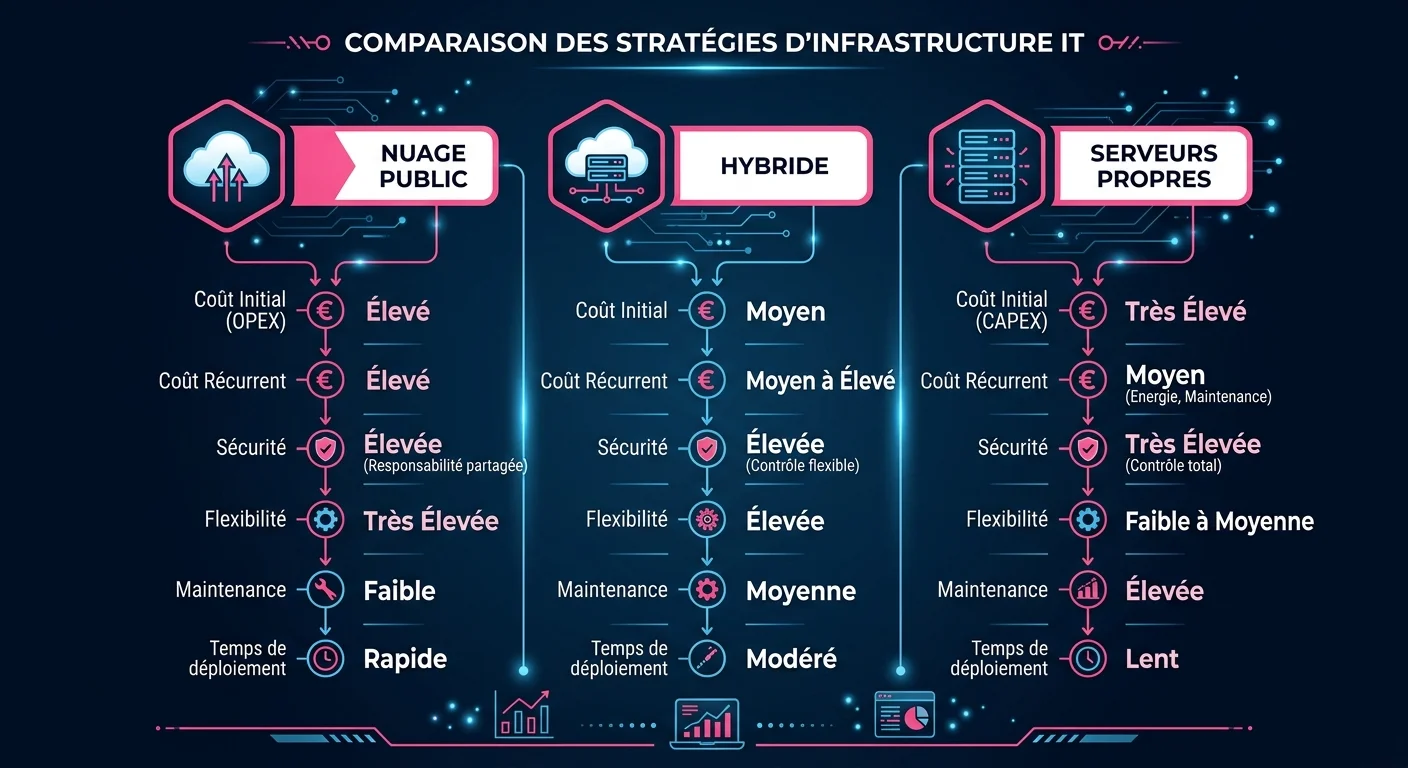
Cloud, hybride, on-premise : arrêtons le mauvais débat
La question n'est pas "cloud ou on-premise ?" mais "quelles données, quel volume, quelle réglementation ?"
Le cloud est systématiquement plus économique si votre charge GPU est inférieure à 60-70 % d'utilisation. En dessous de 12 heures de calcul intensif par jour, louer est moins cher qu'acheter. À l'inverse, pour des workloads intensifs et continus, l'on-premise devient compétitif à partir de la deuxième ou troisième année.
Selon une analyse de Numspot citant Gartner, 90 % des entreprises adopteront une approche cloud hybride d'ici 2027. Le modèle hybride - cloud souverain pour les données critiques, on-premise pour les workloads stratégiques intenses, cloud public pour les pics de charge - s'impose comme l'architecture de référence.
Une approche hybride bien orchestrée peut être 20 à 35 % moins chère qu'un cloud pur sur le long terme, tout en offrant un débit IA comparable. La containerisation (Docker, Kubernetes) et l'autoscaling permettent quant à eux de réduire les dépenses d'infrastructure IA de 30 à 50 % par rapport à des clusters statiques surdimensionnés.
L'enjeu RGPD qui change tout pour les entreprises françaises
La souveraineté des données n'est pas un sujet réservé à l'administration publique. Dès que vous traitez des données personnelles de clients, employés ou partenaires dans une infrastructure IA, le RGPD s'applique. Et là, le choix du cloud devient une décision juridique autant que technique.
Les hyperscalers américains (AWS, Azure, Google Cloud) sont soumis au Cloud Act américain. Même si vos données sont stockées dans un data center en France, les autorités américaines peuvent légalement y accéder dans certaines conditions. Pour des données médicales, juridiques ou touchant à la propriété intellectuelle, ce risque n'est pas théorique.
La qualification SecNumCloud de l'ANSSI garantit un niveau de souveraineté effectif. En 2026, neuf prestataires sont qualifiés en France, et douze candidatures supplémentaires sont en cours d'instruction. L'État français lui-même a basculé : 84 millions d'euros de commandes cloud ont été passés sur le marché interministériel en 2025, en hausse de 62 % par rapport à 2024, dont une part croissante vers des offres souveraines.
Pour aller plus loin sur ce sujet, notre article sur l'IA hébergée en France et le RGPD couvre les obligations concrètes selon le type de données traitées.
Ce que ça coûte vraiment : un cadrage honnête
Voici un comparatif réaliste pour un projet IA de taille intermédiaire (équipe de 50 à 200 personnes, usage quotidien) :
| Composant | Cloud (mensuel estimé) | On-premise (coût initial) |
|---|---|---|
| Compute GPU (inférence 8h/jour) | ~540 € HT (L4 OVHcloud) | 15 000-25 000 € (serveur équipé d'un GPU A10 24 Go) |
| Modèle LLM hébergé | 150-2 000 € HT (API) | Compute inclus si on-prem |
| Infrastructure RAG (embedding + vector DB) | 500-3 000 € HT | Serveur dédié 5 000-15 000 € |
| Orchestration et monitoring | 0 à 500 € HT (outils open source) | Temps équipe interne |
Source : OVHcloud tarifs GPU publics, données marché H100 décembre 2025, estimations RAG production.
Ces chiffres ne sont pas universels. Un projet documentaire simple avec pgvector et un modèle léger peut démarrer sous 200 € par mois. Un projet de traitement en temps réel avec des dizaines de milliers de requêtes par heure et des contraintes HDS multipliera ces coûts par 10 à 50.
Par où commencer : une approche en 3 phases
L'erreur classique est de vouloir construire l'infrastructure complète avant d'avoir prouvé la valeur métier. Voici une séquence qui fonctionne :
Phase 1 - POC via API (0 à 4 semaines) : Utiliser les API de modèles hébergés (OpenAI, Mistral, Anthropic) pour valider que le cas d'usage délivre de la valeur. Aucun GPU à gérer, aucune infrastructure à maintenir. L'objectif n'est pas la production : c'est la preuve de concept.
Phase 2 - Infrastructure minimale (1 à 3 mois) : Si le POC prouve la valeur, passer à une infrastructure hybride légère. Une instance cloud GPU pour l'inférence, une base vectorielle pour le RAG, un monitoring basique. C'est là que les arbitrages cloud/souveraineté entrent en jeu.
Phase 3 - Internalisation progressive : Si les volumes et les contraintes réglementaires le justifient, internaliser partiellement le compute et les données. Ce n'est pas une décision à prendre avant d'avoir validé le modèle économique.
Avant de lancer quoi que ce soit, un diagnostic flash IA en 5 jours permet de cadrer les cas d'usage prioritaires et d'éviter d'investir dans une direction sans ROI.
Une fois l'infrastructure en place, la question suivante est généralement de connecter vos modèles IA à vos outils métier existants - CRM, ERP, outils support - pour que l'infrastructure produise un impact mesurable au quotidien.
Ce qui bloque le plus en pratique
L'infrastructure technique n'est rarement le vrai problème. Ce qui bloque vraiment :
- La qualité des données source : un RAG sur des documents mal structurés donnera des réponses incohérentes, peu importe le GPU.
- L'absence de propriétaire métier : une infrastructure IA sans quelqu'un responsable des résultats finit en projet orphelin.
- La gouvernance des modèles : quel modèle a répondu quoi, à qui, sur quelle version ? Sans traçabilité, impossible d'améliorer ou d'auditer.
- Les droits d'accès : qui peut interroger quelles données via le RAG ? La gestion des droits dans une base vectorielle est souvent implémentée après coup.
Si vous souhaitez qu'une équipe externe cadre et déploie cette infrastructure pour vous, notre pôle agence IA accompagne les ETI et PME de la phase POC au passage en production.
FAQ
Faut-il acheter des GPU on-premise pour utiliser un LLM en entreprise ?
Non. La grande majorité des projets IA en entreprise démarrent et fonctionnent durablement via des API cloud ou des instances GPU à la demande. L'achat on-premise ne devient rentable qu'au-delà d'un volume d'utilisation élevé et continu, ou lorsque des contraintes de souveraineté empêchent l'usage de solutions cloud externes.
Quelle différence entre un modèle accessible via API et un modèle hébergé en propre ?
Via API, vous envoyez vos données au serveur du fournisseur (OpenAI, Anthropic, Mistral...). C'est simple, sans infra à gérer, mais vos données quittent votre périmètre. Un modèle hébergé en propre tourne sur votre infrastructure (cloud ou on-prem) : vos données ne sortent pas, mais vous êtes responsable du compute, de la maintenance et des mises à jour.
Mon projet IA est-il concerné par le RGPD ?
Oui, dès que vous traitez des données personnelles : noms, emails, numéros de téléphone, historiques d'achat, tickets support. Si vos documents RAG contiennent ce type d'informations, le RGPD s'applique à la collecte, au stockage et au traitement. La localisation des données et le choix du prestataire cloud sont des décisions à prendre avec votre DPO.
Combien de temps faut-il pour avoir une infrastructure IA opérationnelle ?
Pour un POC avec API externe : 1 à 2 semaines. Pour une infrastructure hybride minimale en production : 6 à 12 semaines selon la complexité des données source et les contraintes de sécurité. Une infrastructure complète avec gouvernance, monitoring et RAG sur des données multi-sources : 3 à 6 mois pour un premier déploiement stable.