

RAG souverain en France : pgvector, embeddings EU et évaluation RAGAS

La plupart des équipes qui déploient un RAG aujourd'hui s'appuient sur des API d'embeddings et des bases vectorielles hébergées aux États-Unis. Le problème : les données de l'entreprise traversent des infrastructures hors RGPD, et la dépendance à un fournisseur américain peut devenir un frein légal ou commercial.
Si votre équipe fait déjà tourner PostgreSQL, vous avez 80 % de l'infrastructure RAG souveraine sous la main. pgvector, un modèle d'embeddings hébergé chez Scaleway ou OVHcloud, et RAGAS pour l'évaluation : c'est l'essentiel du stack.
Cet article couvre la mise en place technique, le choix des modèles d'embeddings EU, et les métriques d'évaluation qui révèlent réellement si votre pipeline fonctionne.
Pourquoi pgvector plutôt qu'une base vectorielle dédiée
Les bases vectorielles dédiées (Pinecone, Weaviate, Qdrant) ont leur place dans des architectures à très grande échelle. Pour la majorité des projets RAG en entreprise, elles introduisent une complexité opérationnelle injustifiée.
pgvector est une extension PostgreSQL open source qui ajoute la recherche vectorielle directement dans votre base de données existante. Selon la documentation officielle, elle supporte des vecteurs jusqu'à 16 000 dimensions, les index HNSW et IVFFlat, et six fonctions de distance (cosinus, L2, L1, produit interne, Hamming, Jaccard). PostgreSQL 13 ou supérieur est requis.
Avantages concrets pour un déploiement souverain :
- Pas d'infrastructure supplémentaire si vous hébergez déjà PostgreSQL
- Transactions ACID sur les vecteurs comme sur n'importe quelle donnée
- Hébergement chez des providers FR qualifiés SecNumCloud (Scalingo, Outscale)
- Requêtes hybrides : filtre SQL et recherche vectorielle dans la même requête
Pour un agent IA d'analyse documentaire ou un chatbot interne connecté à une base de connaissances, pgvector est la solution la plus pragmatique et la plus souveraine.
HNSW ou IVFFlat : le bon choix d'index
C'est la décision technique qui aura le plus d'impact sur les performances en production. La documentation pgvector précise que les colonnes indexées sont limitées à 2 000 dimensions (vous pouvez stocker des vecteurs plus grands, mais ils ne peuvent pas être indexés directement).
HNSW (Hierarchical Navigable Small World) construit un graphe de navigation. La recherche est logarithmique et très rapide en query time. Le coût : un build plus long et une empreinte mémoire plus élevée. C'est le bon choix pour un RAG en production avec des requêtes fréquentes et des documents qui évoluent.
IVFFlat partitionne les vecteurs en clusters. Build rapide, mémoire plus faible. Les performances de recall se dégradent quand le dataset grossit au-delà de quelques centaines de milliers de vecteurs. C'est adapté pour un POC ou un corpus stable et limité.
Pour un RAG d'entreprise avec des documents qui évoluent, HNSW est le choix par défaut :
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);Le paramètre m contrôle le nombre de connexions par nœud (plus élevé signifie meilleur recall et plus de mémoire). ef_construction contrôle la qualité du build (valeur entre 64 et 200 pour la plupart des cas d'usage).
Choisir un modèle d'embeddings souverain
Le choix du modèle d'embeddings est aussi important que celui de la base vectorielle. Un mauvais modèle, mal adapté au français ou hébergé hors EU, compromettra à la fois la qualité du RAG et la conformité RGPD.
Deux options principales pour héberger en Europe :
Scaleway Generative APIs
Scaleway propose via ses Generative APIs le modèle BGE-Multilingual-Gemma2, classé premier au benchmark MTEB en français et en polonais. Les datacenters sont en France (Paris) et aux Pays-Bas (Amsterdam).
Pour les projets avec des documents techniques ou juridiques en français, BGE-Multilingual-Gemma2 est difficile à battre dans l'espace EU. La plupart des pipelines RAG utilisent 768 dimensions, une valeur bien couverte par ce modèle.
OVHcloud AI Endpoints
OVHcloud propose via ses AI Endpoints le modèle multilingual-e5-base (768 dimensions), compatible LangChain, hébergé en France. OVHcloud est certifié SecNumCloud sur son offre Hosted Private Cloud, le niveau de qualification ANSSI le plus exigeant pour les données sensibles.
Pour les projets nécessitant un hébergement SecNumCloud (secteur public, santé, défense), OVHcloud est souvent le seul choix viable. Pour les PME, Scaleway offre en général une meilleure expérience développeur (API plus simple, tarification plus lisible).
Notre benchmark des providers IA souverains FR/EU compare en détail les performances et les certifications de ces solutions.
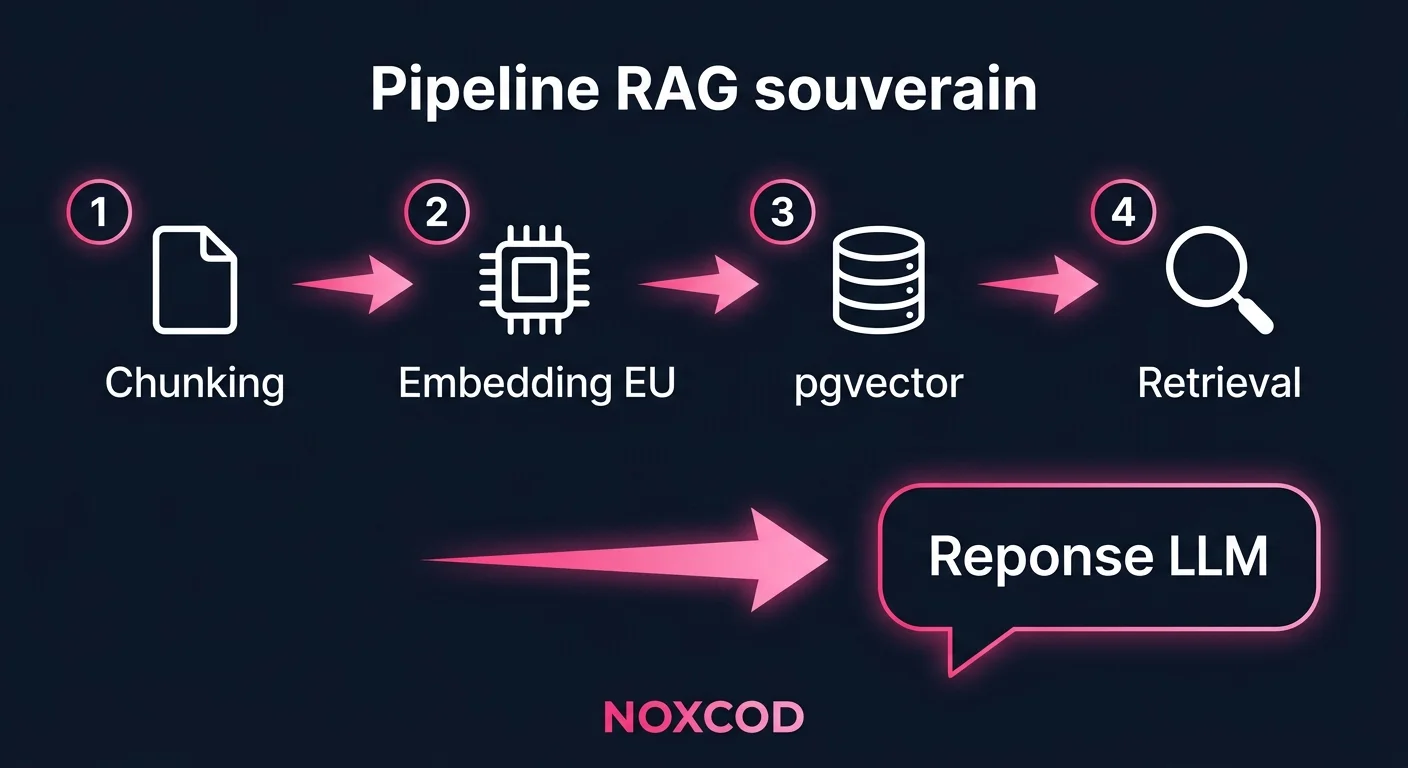
Assembler le pipeline RAG souverain
Un pipeline RAG minimal comprend quatre étapes : chunking, embedding, indexation et retrieval. Voici les choix techniques qui ont de l'importance.
Chunking
Le chunking est sous-estimé. Un chunk trop grand noie le contexte pertinent. Un chunk trop petit perd la cohérence sémantique. Pour des documents d'entreprise (contrats, fiches produit, documentation interne), un chunk de 400 à 600 tokens avec un chevauchement de 10 à 15 % donne de bons résultats en pratique.
Si vos documents sont structurés (PDF avec sections, Markdown), le chunking sémantique par section est préférable au chunking par taille fixe.
Schéma PostgreSQL
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
metadata JSONB,
embedding VECTOR(768),
created_at TIMESTAMPTZ DEFAULT NOW()
);
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops);Le champ metadata en JSONB permet de stocker la source, le titre et la date du document, puis d'appliquer des filtres SQL avant la recherche vectorielle. C'est un avantage décisif de pgvector sur les bases vectorielles pures : pas besoin d'une infrastructure séparée pour les métadonnées.
Requête hybride avec filtre
SELECT content, metadata,
1 - (embedding <=> $1::vector) AS similarity
FROM documents
WHERE metadata->>'department' = 'legal'
AND created_at > NOW() - INTERVAL '1 year'
ORDER BY embedding <=> $1::vector
LIMIT 5;L'opérateur <=> calcule la distance cosinus. Le filtre SQL sur metadata réduit l'espace de recherche avant l'ANN (approximate nearest neighbor), ce qui améliore à la fois la précision et la latence.
LLM hébergé en France
Pour le composant de génération, les mêmes providers s'appliquent. Si la souveraineté est une contrainte forte, Scaleway propose Mistral et Llama via ses Generative APIs. Nous avons couvert les cas d'usage dans notre article sur les assistants IA hébergés en France conformes au RGPD.

Évaluer le RAG avec RAGAS
Un RAG non évalué est un RAG non fiable. Les équipes qui sautent l'évaluation découvrent les problèmes en production, souvent via des utilisateurs frustrés ou des réponses incorrectes sur des documents critiques.
RAGAS est un framework Python open source pour évaluer les pipelines RAG. Publié en 2023, il fournit des métriques de référence sans annotation humaine, ce qui le rend intégrable directement dans un pipeline CI/CD.
Les métriques qui comptent vraiment
Faithfulness : est-ce que la réponse générée est factuellement cohérente avec les chunks récupérés ? Un score bas indique que le LLM hallucine ou ignore le contexte fourni.
Context Recall : est-ce que les chunks pertinents ont été récupérés ? Un score bas pointe vers un problème d'embedding ou d'index, pas de génération.
Context Precision : parmi les chunks récupérés, quelle proportion est réellement utile ? Un score bas signifie que vous récupérez du bruit, souvent causé par un chunking trop grossier ou un k (nombre de résultats) trop élevé.
Answer Relevancy : la réponse répond-elle à la question posée ? Évalue la qualité de la génération finale.
En pratique, les problèmes les plus courants sont :
- Context Recall faible : changer le modèle d'embeddings ou la stratégie de chunking
- Faithfulness faible : ajuster le prompt système pour contraindre la génération au contexte
- Context Precision faible : réduire
kou ajouter un re-ranking
Intégration minimale
from ragas import evaluate
from ragas.metrics import faithfulness, context_recall, context_precision
result = evaluate(
dataset=my_eval_dataset,
metrics=[faithfulness, context_recall, context_precision],
llm=my_llm, # votre LLM hébergé en France
embeddings=my_emb # votre modèle d'embeddings EU
)Le dataset contient des triplets (question, réponse générée, chunks récupérés). RAGAS permet aussi de générer automatiquement un dataset de test à partir de vos documents, ce qui facilite l'évaluation continue sans annotation manuelle.
Pour les équipes qui construisent des agents IA sur mesure, l'évaluation RAGAS permet de valider chaque évolution du pipeline avant mise en production.
Contexte : pourquoi la souveraineté IA devient incontournable
La France comptait 1 000 start-ups IA en 2025, contre 502 en 2021, et s'est classée 5ème mondiale selon le Global AI Index 2024. Les 109 milliards d'euros annoncés lors du Sommet de l'IA de Paris en 2025 incluent un volet important sur les infrastructures souveraines et les modèles de fondation européens.
L'AI Act européen, entré en vigueur en 2024, renforce les exigences de traçabilité et de localisation des données pour les systèmes IA à risque élevé. Pour les entreprises françaises, un RAG hébergé sur des infrastructures EU n'est plus seulement un avantage compétitif, c'est un prérequis de conformité pour certains secteurs.
Pour aller plus loin sur les choix d'infrastructure, notre agence IA accompagne les projets de A à Z.
FAQ
pgvector peut-il tenir en charge sur un corpus de plusieurs millions de documents ?
Oui, avec les bonnes configurations. L'index HNSW a une complexité de recherche logarithmique qui passe à l'échelle. PostgreSQL supporte jusqu'à 32 To par table non partitionnée, ce qui couvre largement la plupart des cas d'usage enterprise. Au-delà de quelques dizaines de millions de vecteurs, le partitionnement de table PostgreSQL s'impose.
Quelle dimension choisir pour les embeddings ?
768 dimensions est un bon compromis (BGE-Multilingual-Gemma2 ou multilingual-e5-base). Les modèles à 1 536 dimensions offrent une meilleure précision mais consomment deux fois plus de mémoire d'index et de stockage. Pour la plupart des RAG documentaires en français, 768 dimensions avec un modèle multilingue entraîné sur du corpus FR donne de meilleurs résultats qu'un modèle anglophone à 1 536 dimensions.
RAGAS fonctionne-t-il avec des LLM hébergés en France ?
Oui. RAGAS accepte n'importe quel LLM compatible LangChain ou LlamaIndex. Vous pouvez configurer Mistral Small sur Scaleway ou un modèle OVHcloud comme juge d'évaluation. Le seul prérequis est que le LLM juge comprenne le français pour évaluer des réponses en français.
Faut-il un re-ranking pour améliorer la précision ?
Si votre Context Precision RAGAS est inférieure à 0,6, un re-ranker vaut la peine. Les modèles de re-ranking re-scorent les k chunks récupérés et ne gardent que les plus pertinents avant de les passer au LLM. Le gain de précision est souvent significatif sur des corpus hétérogènes (mélange de contrats, de fiches produit et de notes internes par exemple).


