


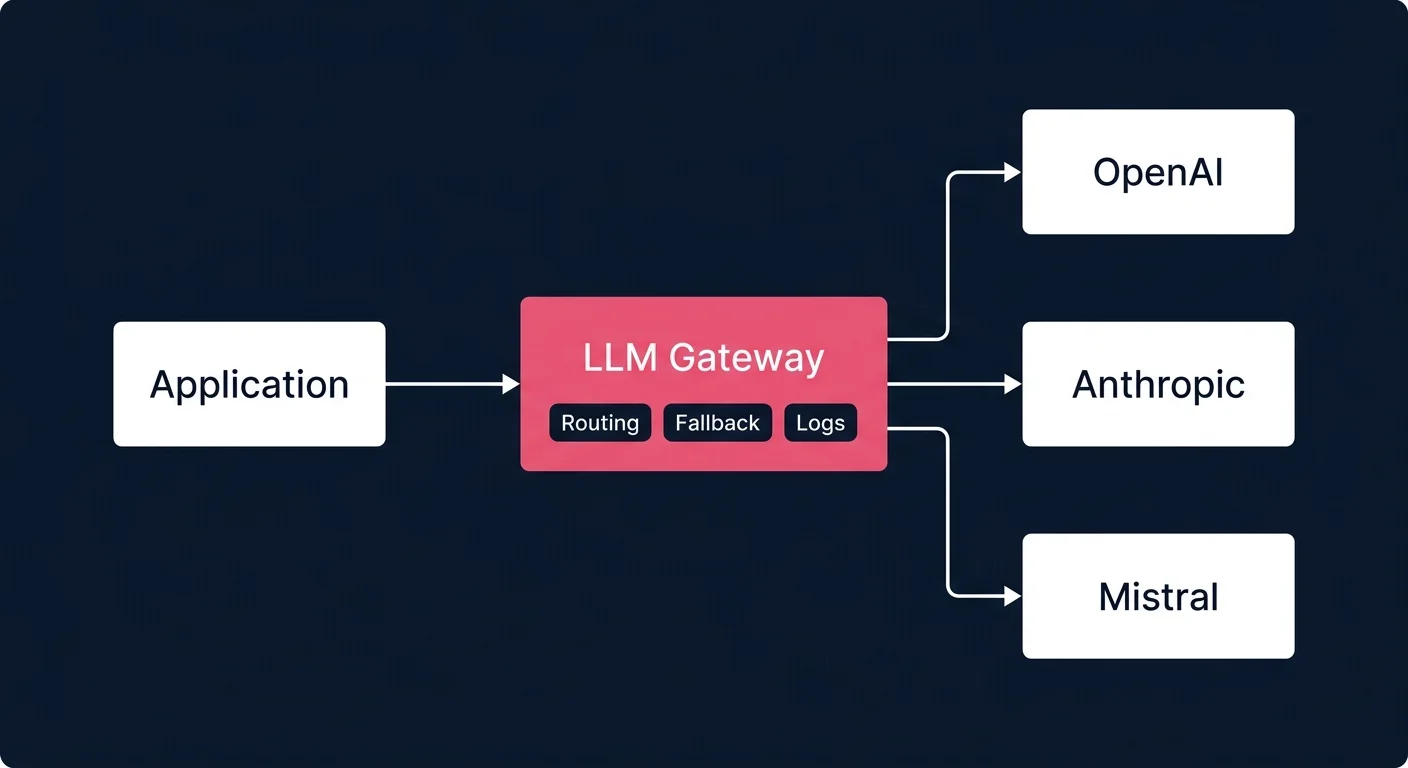
Sans gateway, chaque changement de modèle implique de modifier votre code. Vous passez d'OpenAI à Anthropic : c'est une réécriture partielle. Vous ajoutez un fallback vers Groq si OpenAI est rate-limité : c'est une logique à implémenter vous-même. Multipliez ça par cinq projets et vous avez un problème structurel, pas juste un inconvénient.
L'idée derrière un LLM gateway est simple : une seule URL, un seul format d'API, et derrière, n'importe quel fournisseur de modèles. Le routing, les fallbacks, le logging et la gestion des coûts se gèrent au niveau du gateway, pas dans chaque application.
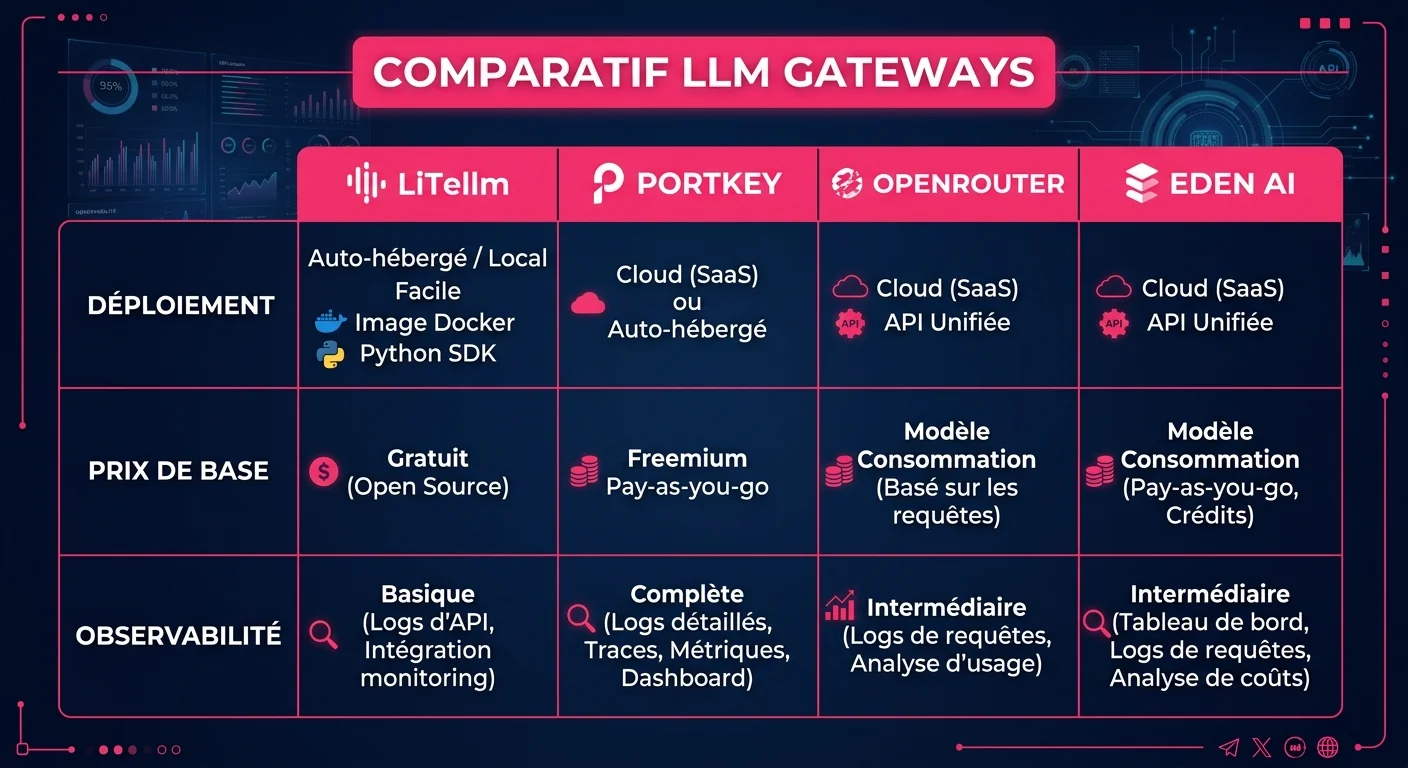
Quatre outils dominent ce segment : LiteLLM, Portkey, OpenRouter et Eden AI. Leurs approches sont assez différentes pour que le choix dépende autant de votre contexte que de leurs fonctionnalités.
Ce que "compatible OpenAI" signifie en pratique
OpenAI a publié son API en 2020. En quelques années, le format /v1/chat/completions est devenu le standard de facto : Anthropic, Mistral, Groq, Together AI, et des dizaines d'autres providers ont adopté des endpoints identiques ou très proches. Les principaux frameworks - LangChain, LlamaIndex, Semantic Kernel - ciblent ce format.
Un gateway compatible OpenAI expose exactement ce même format vers l'extérieur, quelle que soit l'API sous-jacente. Pour changer de provider, vous modifiez deux lignes : base_url et api_key. Le reste du code ne bouge pas.
C'est la condition préalable pour gérer plusieurs modèles en production. Sans standardisation, chaque provider a ses particularités : paramètres différents, formats de réponse légèrement divergents, gestion des erreurs spécifique. Le gateway absorbe cette complexité.
LiteLLM : le proxy open source de référence
LiteLLM est le projet de référence pour qui veut garder le contrôle complet de son infrastructure. Il cumule 48 100 étoiles GitHub (au 24 mai 2026) et est utilisé dans plus de 21 400 projets déclarés sur GitHub - des chiffres qui reflètent une adoption réelle dans la communauté dev, pas juste de la visibilité marketing.
Son fonctionnement est direct : un proxy Python que vous déployez sur votre infrastructure, qui expose une API /v1/chat/completions et route vers 100+ providers. Azure OpenAI, Bedrock, Anthropic, VertexAI, Ollama en local - tout passe par la même interface.
Ce qui le distingue techniquement par rapport à un simple reverse proxy :
- Virtual keys : vous émettez des clés internes par équipe ou projet, sans jamais exposer vos clés providers réelles dans le code des applications
- Budget limits : plafonner les dépenses par clé, par équipe, par utilisateur - utile si plusieurs équipes partagent les mêmes crédits LLM
- Router avec retry et fallback automatiques : si OpenAI renvoie une erreur de rate limit, LiteLLM reroute vers une autre configuration sans que votre application le voie
- Cost tracking : suivi des dépenses par provider, par clé, par projet via un dashboard admin
La version open source couvre l'essentiel. Les fonctionnalités enterprise - SSO, SCIM, audit logs complets, RBAC granulaire, intégration secret managers - font l'objet d'un plan sur devis. LiteLLM propose aussi un hébergement managé (testé à 1 000 requêtes/seconde, certifié SOC 2 Type 2 et ISO 27001) pour les équipes qui veulent les garanties enterprise sans opérer l'infra.
La limite principale est structurelle : vous opérez l'infrastructure. Mises à jour, monitoring, haute disponibilité - c'est votre responsabilité. C'est acceptable pour une équipe tech expérimentée, moins pour une startup qui veut aller vite.
Portkey : l'observabilité comme différenciant
Portkey prend un angle différent. Là où LiteLLM est d'abord un proxy avec des fonctionnalités de gestion, Portkey est d'abord une plateforme d'observabilité LLM avec un gateway intégré. Ce n'est pas juste un positionnement marketing : ça se traduit dans les fonctionnalités.
Les plans reflètent cette priorité. Le tier gratuit inclut 10 000 logs enregistrés par mois avec une rétention de 3 jours. Le plan Production (49 USD HT/mois) monte à 100 000 logs, 90 jours de rétention, des templates de prompts illimités et le contrôle d'accès par rôle. Au-delà : tarification à 9 USD par tranche de 100 000 requêtes supplémentaires.
Ce que Portkey apporte que les autres n'ont pas nativement :
- Semantic caching : les requêtes similaires - pas identiques, mais sémantiquement proches - retournent depuis le cache. Pour les use cases avec forte redondance (chatbots FAQ, support, documentation search), ça réduit à la fois la latence et les coûts réels
- Guardrails : validation et filtrage des sorties LLM configurables via le dashboard, sans toucher au code
- Prompt versioning : versionner et tester différentes versions de prompts sans redéployer l'application
- Traces détaillées : visualiser chaque appel LLM avec le contexte complet - utile pour débugger des agents multi-step
L'inconvénient est le lock-in SaaS : vos logs et traces transitent par les serveurs Portkey. Pour les équipes avec des contraintes RGPD strictes, le plan Enterprise (déploiement private cloud, VPC hosting) est nécessaire.
OpenRouter : le catalogue, pas le gateway
OpenRouter est souvent mis dans le même sac que LiteLLM et Portkey, mais la comparaison s'arrête là : OpenRouter est un service externe géré, pas un proxy que vous déployez. Il vous donne accès à 400+ modèles de 60+ providers via une seule API et une seule facture.
Les chiffres publiés par OpenRouter donnent l'échelle : 80 trillions de tokens traités par mois, 8 millions d'utilisateurs, 250 000 applications intégrées. Ce volume reflète une réalité : OpenRouter est devenu le chemin le plus court pour accéder à la breadth des modèles disponibles sans gérer plusieurs comptes providers.
La structure tarifaire est simple : OpenRouter prélève 5,5% sur l'achat de crédits, et passe les prix providers sans surcharge à l'usage. Si Claude Sonnet 4.6 coûte 3 USD par million de tokens chez Anthropic, il coûte 3 USD chez OpenRouter - les 5,5% sont prélevés au dépôt initial, pas à chaque requête.
Pour les modèles open source (DeepSeek, Llama, Mistral), plusieurs "providers" concurrents proposent des tarifs différents pour le même modèle. OpenRouter peut router automatiquement vers le moins cher selon votre paramètre provider. C'est l'une des fonctionnalités distinctives pour les équipes sensibles aux coûts sur de gros volumes.
Ce qu'OpenRouter ne remplace pas : vous n'avez aucun contrôle sur l'infrastructure. Impossible de déployer votre propre instance. Si votre projet nécessite un hébergement RGPD strict, des données sur des serveurs français, ou un SLA contractuel, OpenRouter n'est pas adapté. Pour ça, revenez à LiteLLM self-hosted ou au plan Enterprise Portkey.
Eden AI : quand la diversité des modalités compte
Eden AI occupe un créneau légèrement différent. Là où LiteLLM, Portkey et OpenRouter sont focalisés sur les LLM texte, Eden AI couvre aussi la vision par ordinateur, l'OCR, la transcription audio et la synthèse vocale via la même API unifiée.
La plateforme revendique 500+ modèles IA et plus de 200 000 développeurs. Son modèle tarifaire est similaire à OpenRouter : 5,5% de frais de plateforme sur les prix providers, sans surcharge par requête.
L'avantage différenciant est dans les pipelines multimodaux. Pour un projet qui mélange extraction de données depuis des PDFs (OCR), transcription d'appels audio et réponse LLM dans le même workflow, Eden AI évite de gérer trois SDKs différents avec trois comptes séparés. Un seul point d'intégration, une seule ligne de facturation.
La limite est symétrique : la profondeur est inférieure à celle des outils spécialisés. Pas de semantic caching, pas de budget limits par équipe, pas de RBAC fin comme LiteLLM, pas de prompt versioning comme Portkey.
Comment choisir entre ces quatre outils
Quatre situations typiques mènent à des choix différents.
Si vous gérez de l'infrastructure et avez des contraintes de conformité, LiteLLM self-hosted est la réponse naturelle. Tout reste sur vos serveurs. Vous émettez vos propres clés, vous intégrez vos secret managers, vous contrôlez qui accède à quoi. La communauté open source assure des mises à jour fréquentes - la v1.86.0 est sortie le 24 mai 2026.
Si vous avez besoin de visibilité sur ce que vos LLMs font en production, Portkey. Les logs structurés, traces et métriques sont ce qu'on trouve rarement dans les autres outils au même niveau de granularité. À 49 USD HT/mois pour le plan Production, c'est justifiable pour une équipe de cinq personnes qui passe du temps à débugger des comportements inattendus sur des agents multi-step.
Si vous prototypez ou testez beaucoup de modèles différents, OpenRouter. Accéder à GPT-5.5, Claude Opus 4.7 et Llama 4 dans la même codebase sans gérer trois clés API et trois comptes séparés, c'est l'usage principal. Pour du développement exploratoire, c'est difficile à battre.
Si votre pipeline mélange LLM, vision et audio, Eden AI mérite d'être évalué. Le gain est dans la simplification des intégrations multimodales, pas dans les fonctionnalités gateway LLM pures.
Une approche mixte est aussi fréquente : OpenRouter pour le prototypage et les tests de modèles, LiteLLM en production pour garder le contrôle et la conformité. Les deux outils sont compatibles : LiteLLM peut router vers OpenRouter comme provider.
Pour aller plus loin sur l'intégration de ces outils dans une architecture IA complète, le guide mettre en place une infrastructure IA en entreprise couvre les décisions d'architecture au-delà du choix du gateway. Si vous utilisez n8n pour orchestrer des agents, la combinaison n8n + MCP change la façon dont vous exposez vos workflows à des agents Claude ou GPT. Et pour choisir les bons LLMs selon vos use cases, le comparatif Claude Code, Cursor et Copilot aborde le contexte des outils de code IA qui s'appuient sur ces mêmes APIs.
Si votre besoin dépasse le choix d'un outil et que vous construisez une plateforme IA interne, notre pôle agents IA peut vous accompagner sur l'architecture complète.
Questions fréquentes
LiteLLM est-il vraiment gratuit en production ?
La version open source est gratuite à déployer, y compris en production. Vous payez votre infrastructure (serveur, Docker) et les coûts des APIs providers que vous appelez. Les fonctionnalités enterprise (SSO, audit logs, SCIM) sont sur un plan payant à tarif sur devis. Pour la grande majorité des projets, la version open source est suffisante.
OpenRouter respecte-t-il les règles RGPD ?
OpenRouter ne stocke pas les prompts et completions par défaut - seulement les métadonnées (timestamps, modèle utilisé, nombre de tokens). Cependant, vos requêtes transitent par les serveurs d'OpenRouter avant d'atteindre le provider. Si vos requêtes contiennent des données personnelles, ce transit représente un transfert de données à documenter dans votre registre RGPD. Pour des données sensibles, LiteLLM self-hosted ou un plan Portkey Enterprise en private cloud est plus adapté.
Peut-on combiner plusieurs gateways dans la même architecture ?
Oui, et c'est fréquent. LiteLLM peut utiliser OpenRouter comme l'un de ses providers configurés - vous gardez les virtual keys et le budget tracking de LiteLLM, avec l'accès aux 400+ modèles d'OpenRouter derrière. De même, Portkey peut pointer vers des endpoints LiteLLM. L'approche "gateway devant gateway" ajoute de la latence marginale (<5ms) mais peut combiner les avantages des deux outils selon les contraintes du projet.


